スキャナーで取り込んだ文書をWordやテキストにするOCRというソフトがあります。これは保存や撮影した画像からでも可能なのですが、日本語という縦書レイアウトと漢字文化では難しい側面があります。
この前はWebでOCRできるサイトを紹介したのですが、CANONのスキャナーに付属する「読み取り革命」で同じ画像を処理してみました。まだ使い慣れていないので、Word化は無理でテキストだけ (^_^;)
デフォルト環境では、文字列が勝手に画像や枠組み処理されて使い物になりませんが、領域設定を一度全削除し、領域のプロパティで文字と文字方向を指定すると、少なくとも縦書の文書として処理されます。問題はここから (^.^;
![]()
デフォルト環境 赤が文字横認識、青が画像認識、緑が文字縦認識
![]()
![]()
![]()
テキスト化
OCRは、文字判別と辞書機能が解像度に依存するので、出来るだけ解像度の高い環境でスキャナーを使用する必要があります。もっとも、スキャナーの解像度を目一杯高くすると重くなるので、そこは適当な解像度を探すしかありません。
今回は、両開きで326KBの画像を処理したので文字化けがひどくてダメでした。これの4倍の解像度は必要な気が (;^ω^)
この前はWebでOCRできるサイトを紹介したのですが、CANONのスキャナーに付属する「読み取り革命」で同じ画像を処理してみました。まだ使い慣れていないので、Word化は無理でテキストだけ (^_^;)
デフォルト環境では、文字列が勝手に画像や枠組み処理されて使い物になりませんが、領域設定を一度全削除し、領域のプロパティで文字と文字方向を指定すると、少なくとも縦書の文書として処理されます。問題はここから (^.^;
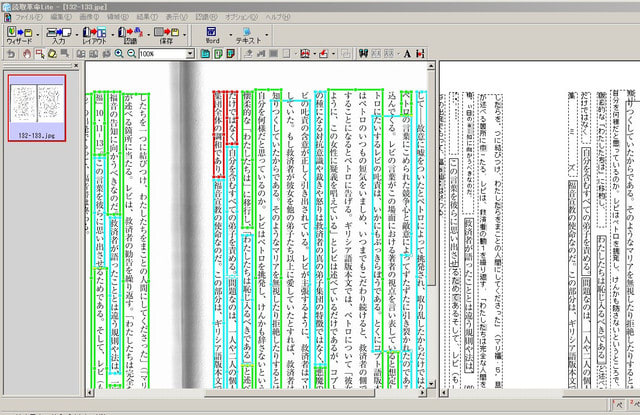
デフォルト環境 赤が文字横認識、青が画像認識、緑が文字縦認識
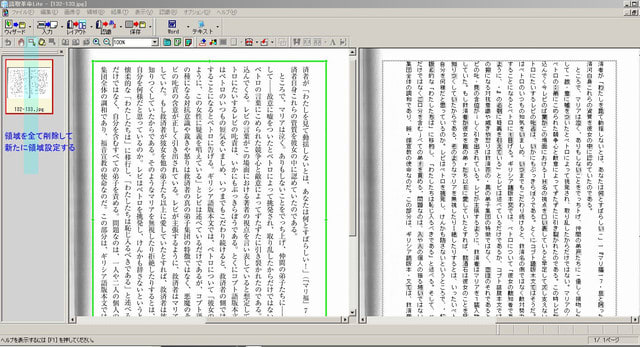
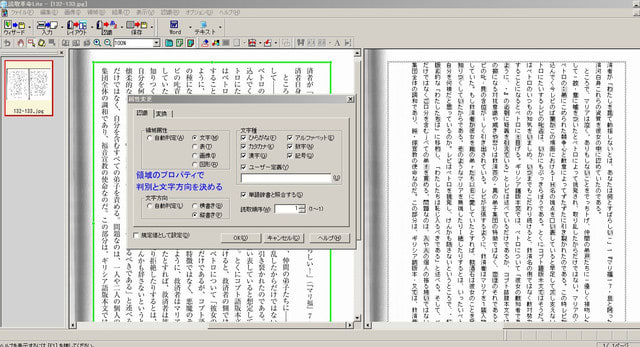
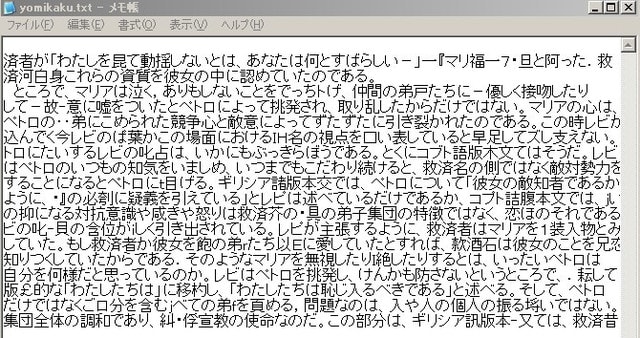
テキスト化
OCRは、文字判別と辞書機能が解像度に依存するので、出来るだけ解像度の高い環境でスキャナーを使用する必要があります。もっとも、スキャナーの解像度を目一杯高くすると重くなるので、そこは適当な解像度を探すしかありません。
今回は、両開きで326KBの画像を処理したので文字化けがひどくてダメでした。これの4倍の解像度は必要な気が (;^ω^)